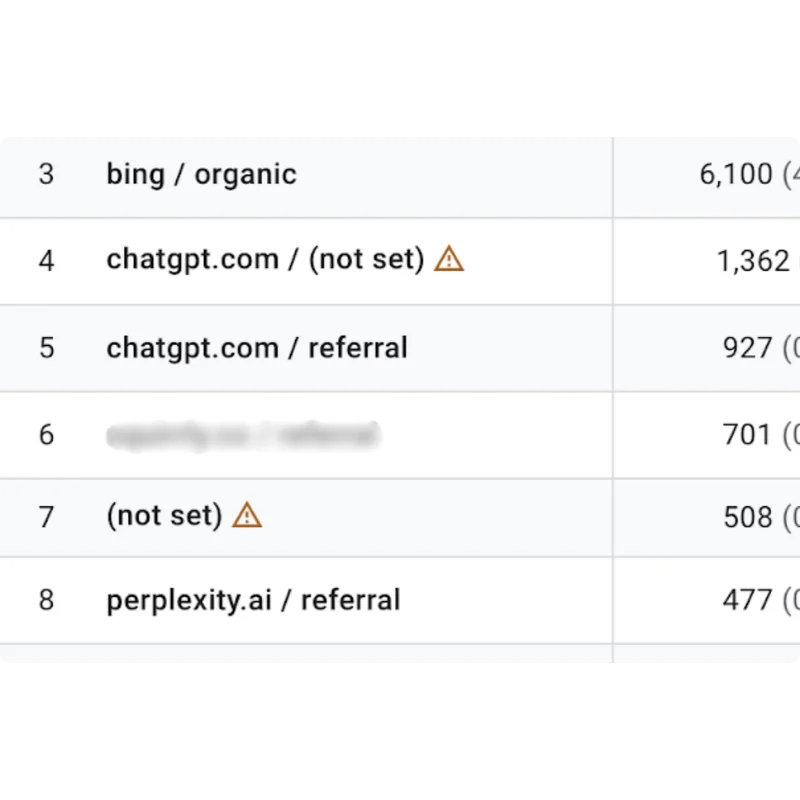
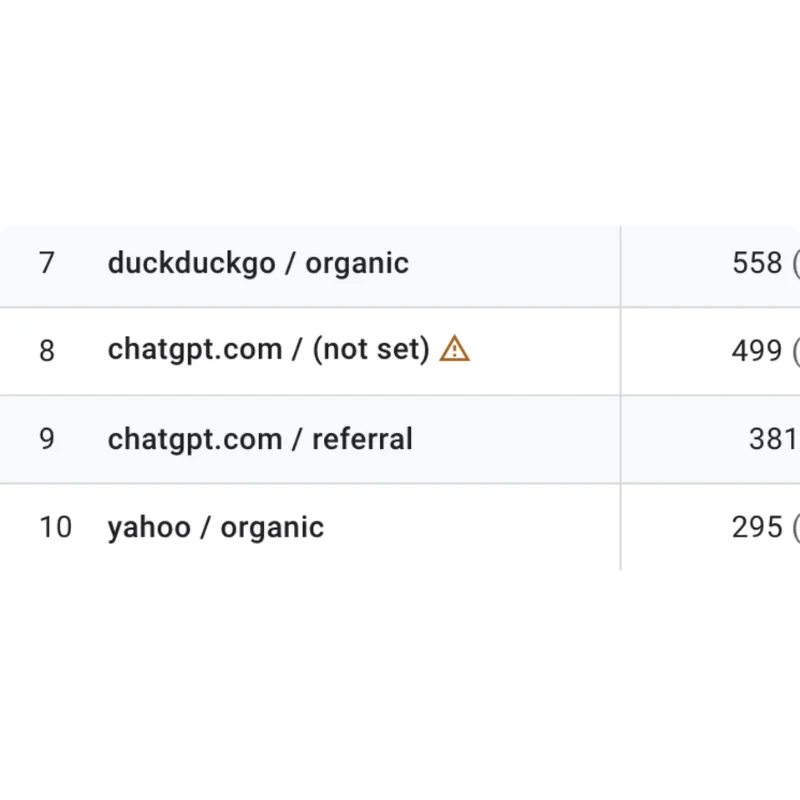
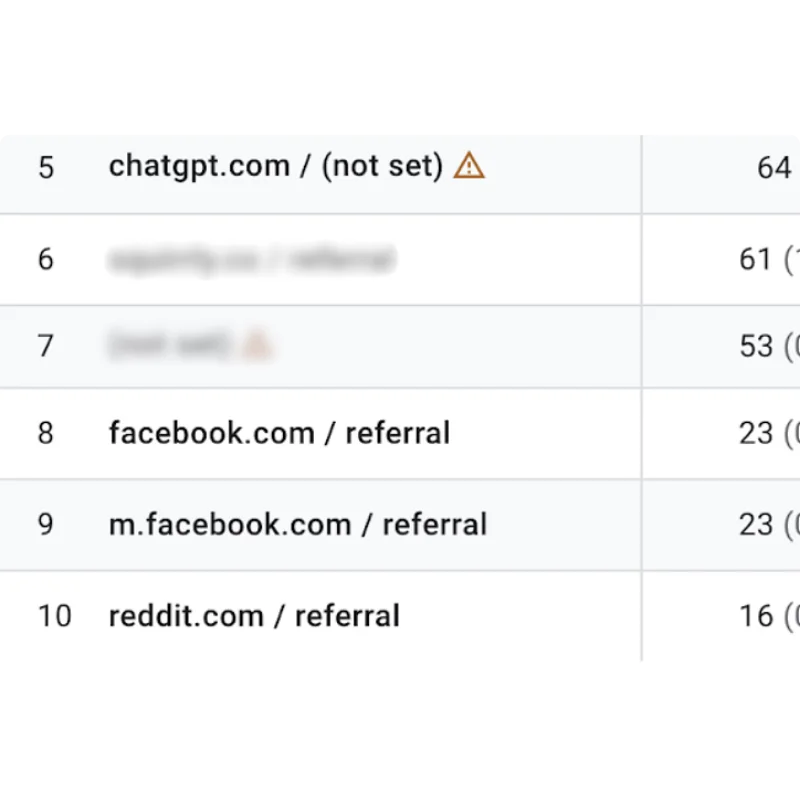
The Data Is In: AI Content Ranks, Converts, a
The Data Is In: AI Content Ranks, Converts, and Grows T...

DeepSeek AI has introduced a groundbreaking method for training large language models (LLMs) through a new reward modeling technique called Self-Principled Critique Tuning (SPCT). This approach could make AI systems much more adaptable and reliable in open-ended, complex domains—where traditional reward models often struggle.
SPCT aims to move beyond domain-specific reward scoring by teaching models to generate their own evaluation principles and use them to critique responses. The result? Smarter, more scalable AI that can improve its performance in real time when given more computational resources.
This innovation has the potential to transform enterprise AI by making models more adaptable to creative, dynamic environments like customer service, content generation, and complex decision-making. While DeepSeek’s model doesn’t yet outperform specialized scalar RMs on simple, verifiable tasks, its promise lies in generalist capabilities and scalability.
Expect this research to influence how LLMs are evaluated and fine-tuned across the AI landscape, potentially becoming a new standard for training future general-purpose models.
Source: https://venturebeat.com/ai/deepseek-unveils-new-technique-for-smarter-scalable-ai-reward-models/
Gateway to AI Adoption. This is the Future of Marketing.

The Data Is In: AI Content Ranks, Converts, and Grows T...

OpenAI’s Sora vs Google’s Veo 3: The Battle for the...

Microsoft Turns Windows Into the First “Agentic OS”...