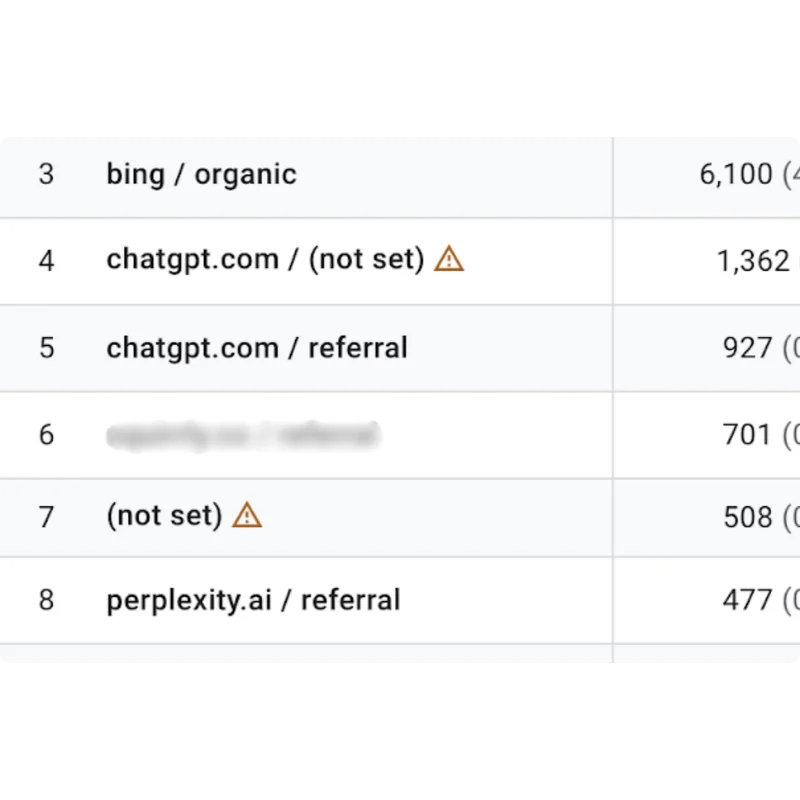
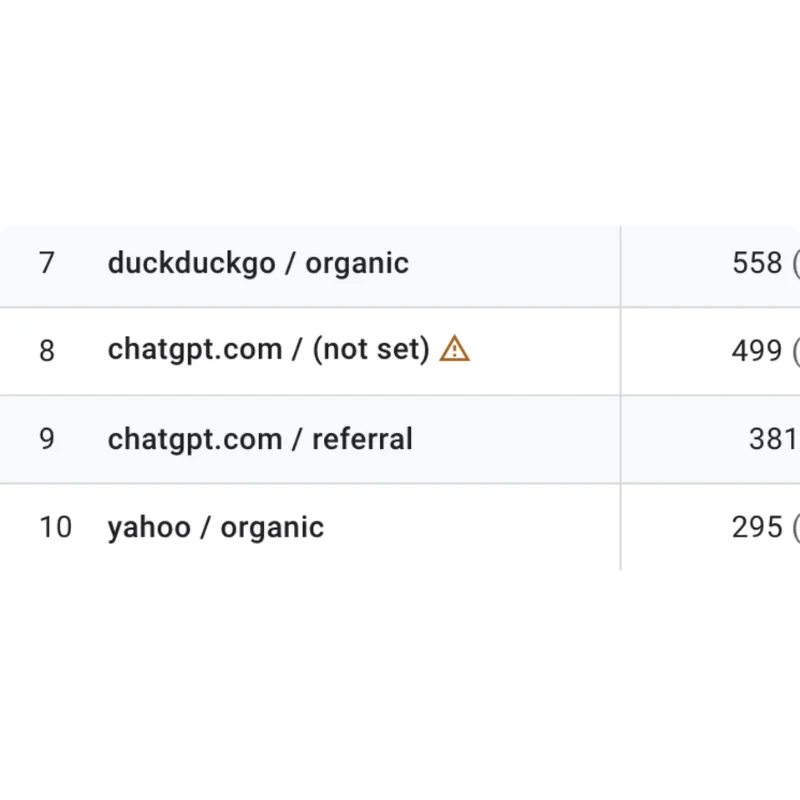
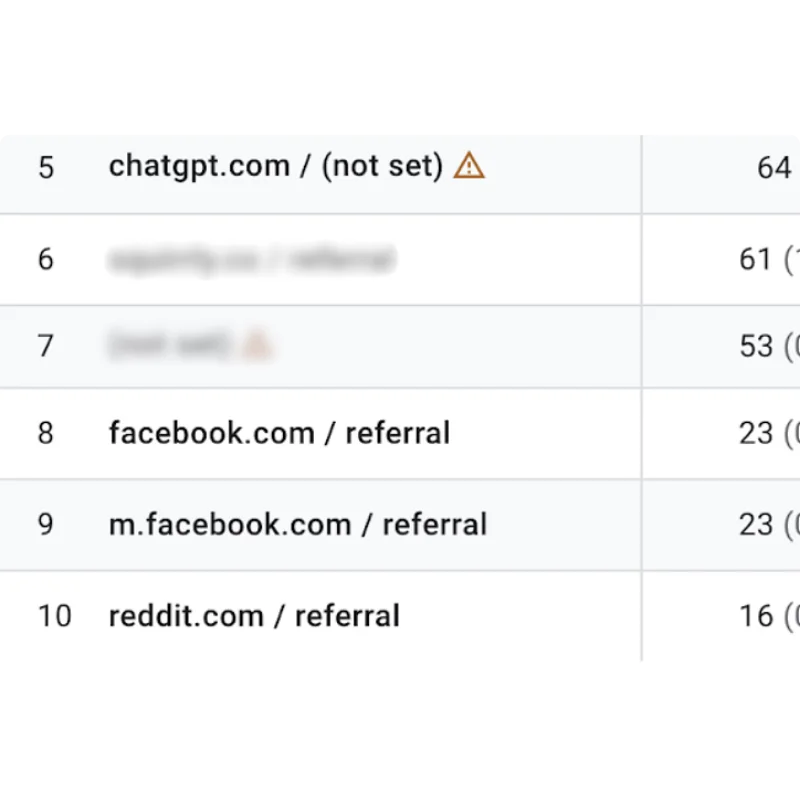
Your Brand Is Being Seen Inside AI Tools Far
Your Brand Is Being Seen Inside AI Tools Far More Than ...

A two-person team at Nari Labs has just dropped Dia, a powerful new open source text-to-speech model—and it’s turning heads across the AI landscape. Built with zero funding and trained on Google TPUs via the Research Cloud, Dia aims to beat industry leaders like ElevenLabs, OpenAI’s gpt-4o-mini-tts, and Google’s NotebookLM podcast tool. What sets it apart? Natural dialogue delivery, emotional tone, and the ability to interpret nonverbal cues like laughter and coughing—all from plain text.
Openly available on GitHub and Hugging Face under an Apache 2.0 license, Dia is already making waves in audio generation communities with example demos showing it outperforming proprietary models. With advanced voice control, voice cloning, and expressive performance baked in, this model isn’t just for coders—it’s built for anyone who wants to generate high-quality spoken content.
Dia represents a significant moment for open source voice tech. It’s a rare example of a small, grassroots AI team challenging the dominance of major players with a model that combines both accessibility and expressiveness. By making it commercially usable out of the box and prioritizing responsible development, Nari Labs is positioning Dia as a go-to solution for developers, educators, content creators, and more.
This isn’t just about better voice synthesis—it’s about democratizing the ability to create digital voices that feel human. And if this is what two people can build without funding, the ripple effects across AI development could be massive.
Gateway to AI Adoption. This is the Future of Marketing.

Your Brand Is Being Seen Inside AI Tools Far More Than ...

Why OpenAI Suddenly Killed Sora (And What It Means) ...

AISQ's Next Level Marketing AI delivers fully automated...